04. Longitudinal Representation
Longitudinal Representation
ND320 AIHCND C01 L03 A04 Longitudinal Representation
*Note: Typo at 3:00 should read "Google".
Longitudinal Representation Key Points
Longitudinal Representation: Patient History
What is a longitudinal data representation?
Another way to view it is a patient history representation. It is basically a way to aggregate all of the visits/encounters that a patient may have in the healthcare system. Having all of this information is ideal to best analyze and diagnose correctly, but the reality is that patient records do not always come cleanly organized and aggregated correctly, in real-world datasets. Luckily, we can use the line and encounter levels to help with that!
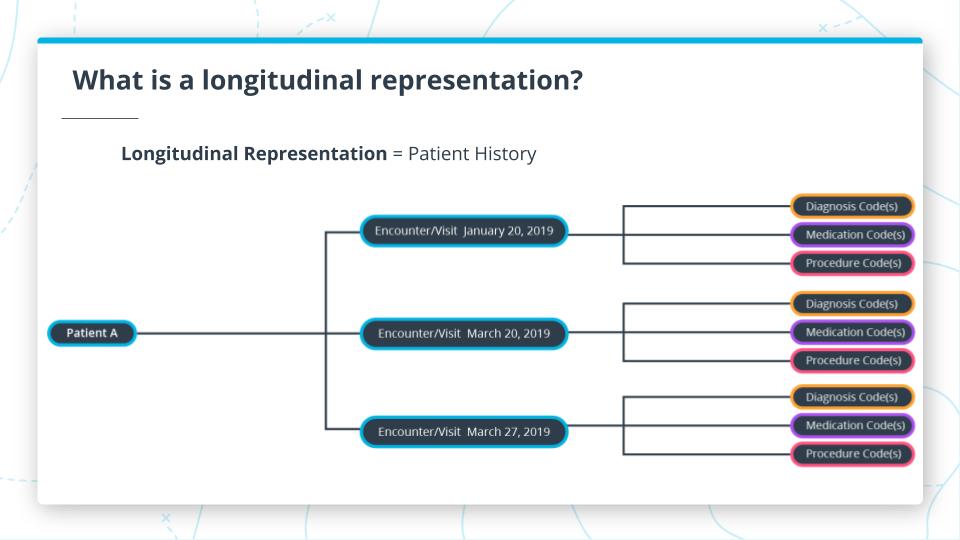
Longitudinal Representation Example
Combining patients together into a dataset and finding a way to aggregate and represent the visits across a patient is the key to being able to unlock powerful insights and analysis.
Challenges and Benefits of Using the Longitudinal Level
Challenges:
- Scaling with this type of data requires vast resources
- Data representation and preparation requires more preparation and validation
- Training vs production/deployment data differences can cause major issues with model predictions
Example: You train this great Model, and it has fantastic results!
However, the data you used for this model had an implicit assumption that you were unaware of :
Only the label for the last encounter for a patient history would be included.
You think that you can always transform the data in production. Right?
Reality: You have put your model into production and things start going haywire.
You are not getting the same results that you anticipated from your trained model. Even with some cross-validation and other augmentation methods, you still see significant model drift. After some analysis of the production data pipeline, you find out that the production use case has an Encounter selected at random from the patient history and information has been duplicated by accident because the information was not leveled correctly.
From this example, you can see how important it is to make sure you, or your data team, have properly aggregated the data.
Benefits:
Even though data preparation and validation are more difficult, there are significant benefits to using a longitudinal representation as it allows you to use a full patient history. This helps to better model changes in state over time. When you can also aggregate other patients longitudinal data together, you can achieve some unbelievable results.
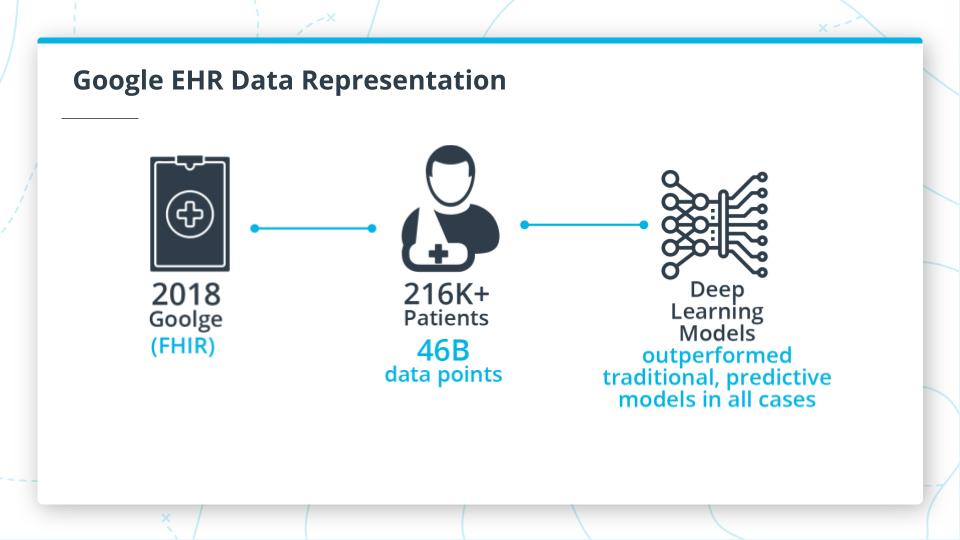
Deep Learning Potential Importance
To further illustrate the importance of having a strong EHR longitudinal data representation, you can look through the links in this section about Google creating a data representation to feed into deep learning models from the Fast Healthcare Interoperability Resources or FHIR standards.
In Google's Nature article, they highlighted the aforementioned challenges with building a longitudinal representation. The 216K+ patients in the dataset were extrapolated to 46B data points! Now imagine attempting to scale this even further with more patients or other types of data like genomic data, clinical trial data, etc. This is where resources like cloud computing have become critical, but even these can be strained with this much data.
As most practitioners know, the data preparation stage is one of the most time consuming, but impactful parts of a data science project. The representation and deep learning models outperformed clinically used traditional predictive models in ALL cases. It is still early days for the healthcare industry as they have just started to consider using deep learning and still barriers exist in using them due to concerns about interpretability. Hopefully, with more studies like this, critical attention to detail and eye on data security and privacy we can bring this practice to the forefront in healthcare.
Additional Links
Longitudinal Level
SOLUTION:
- Scaling the collection and processing of this data can be resource intensive.
- Data cleaning and inspection are key parts of utilizing this data representation.
- There can be differences between training and production data, which can cause major issues.
Reflect
QUESTION:
While creating and working with longitudinal datasets can be a challenge, there is tremendous value to using this level. Go to arXiv and search for longitudinal and EHR? Any interesting papers? Select one and share what you found interesting about it.
ANSWER:
I searched and found this paper from the University of Cambridge and UCLA called A Bayesian Approach to Modelling Longitudinal Data in Electronic Health Records. This paper was very interesting for not only its content but also how many of the topics it includes ties in with the content in this course. I provided a few snippets below but feel free to read the whole paper now that you are have some knowledge about longitudinal EHR data!
- Missing data mentioned - In the "Informative Missing Values" section on page 3, it shares how missing values could indicate decision made by clinicians that could provide implicit information about a patient. This ties back to our understanding of MCAR, MAR, MNAR.
- Demographics - It mentions " fixed demographic information " in the abstract and wanted to note this since this implies that there was some demographic analysis to "fix" the right groups for building the model and ties in with our lesson earlier on this topic.
- Uses Bayesian method because it has the advantage of providing uncertainty estimates. This ties into what we will cover later when we learn about how to use Tensorflow Probability to build uncertainty estimation into our models.